

Image composite du SKA combinant tous les éléments en Afrique du Sud et en Australie. Crédit : SKAO
Depuis plus de 60 ans, les scientifiques recherchent dans le cosmos d’éventuels signes de transmission radio qui indiqueraient l’existence d’une intelligence extraterrestre (ETI). Au cours de cette période, la technologie et les méthodes ont considérablement évolué, mais les plus grands défis demeurent. En plus de n’avoir jamais détecté de signal radio d’origine extraterrestre, il existe un large éventail de formes possibles qu’une telle émission pourrait prendre.
En bref, les chercheurs du SETI doivent supposer à quoi ressemblerait un signal, mais sans le bénéfice d’aucun exemple connu. Récemment, une équipe internationale dirigée par l’Université de Californie à Berkeley et l’Institut SETI a mis au point un nouvel outil d’apprentissage automatique qui simule ce à quoi pourrait ressembler un message provenant d’une intelligence extraterrestre (ETI). Connue sous le nom de Setigen, cette bibliothèque open-source pourrait changer la donne pour les futures recherches du SETI.
L’équipe de recherche était dirigée par Bryan Brzycki, un étudiant diplômé en astronomie de l’université de Berkeley. Il a été rejoint par Andrew Siemion, directeur du Berkeley SETI Research Center, et des chercheurs du SETI Institute, de Breakthrough Listen, du Dunlap Institute for Astronomy & Astrophysics, de l’Institute of Space Sciences and Astronomy, du International Center for Radio Astronomy Research (ICRAR) et du Goergen Institute for Data Science.
Depuis les années 1960, la méthode la plus courante du SETI consiste à rechercher dans le cosmos des signaux radio d’origine artificielle. La première expérience de ce type a été le projet Ozma (avril à juillet 1960), dirigé par le célèbre astrophysicien de Cornell Frank Drake (créateur de l’équation de Drake). Cette étude s’appuyait sur la parabole de 25 mètres du National Radio Astronomy Observatory de Green Bank, en Virginie occidentale, pour surveiller Epsilon Eridani et Tau Ceti à des fréquences d’environ 400 kHz autour de 1,42 GHz.
Ces recherches se sont depuis étendues pour couvrir de plus grandes zones du ciel nocturne, des plages de fréquences plus larges et une plus grande diversité de signaux. Comme l’a expliqué Brzycki à Universe Today par courrier électronique :
« Dans les années 1960, l’idée était de se concentrer sur une région autour d’une fréquence bien connue où l’hydrogène neutre émet un rayonnement dans l’espace interstellaire, à savoir 1,42 GHz. Comme cette émission naturelle est répandue dans toute la galaxie, l’idée est que toute civilisation intelligente la connaîtrait et pourrait cibler cette fréquence pour la transmettre afin de maximiser les chances de détection. Depuis lors, notamment grâce aux progrès rapides de la technologie, la radio du SETI s’est développée sur tous les axes de mesure.
« Nous pouvons désormais prendre des mesures sur une bande passante de plusieurs GHz de manière instantanée. Avec l’amélioration du stockage, nous pouvons collecter d’énormes quantités de données, ce qui permet des observations à plus haute résolution dans les directions du temps et des fréquences. De même, nous avons effectué des relevés des étoiles proches et d’autres directions dans la galaxie, afin de maximiser l’exposition à des directions potentiellement intéressantes dans le ciel. »
Un autre changement majeur a été l’incorporation d’algorithmes basés sur l’apprentissage automatique, conçus pour trouver les transmissions au milieu du bruit de fond radioélectrique du cosmos et pour corriger les interférences radioélectriques (RFI). Les algorithmes employés dans les études du SETI se répartissent en deux catégories : ceux qui mesurent les données des séries temporelles de tension et ceux qui mesurent les données des spectrogrammes de fréquence.
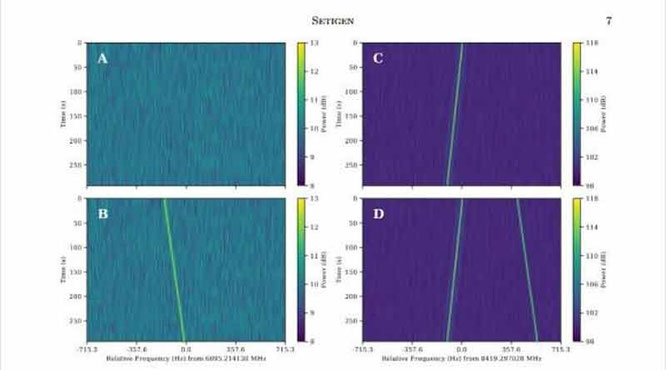
Tracés de spectrogrammes radio créés à partir de trames Setigen. Crédit : Brzycki et al.
« Les données brutes recueillies par une antenne radio sont des mesures de tension ; une onde radio induit un courant dans l’antenne, qui est lu et enregistré sous forme de tension », a déclaré M. Brzycki. « Un radiotélescope n’est en fait qu’une antenne augmentée d’une parabole pour concentrer une plus grande surface de lumière, ce qui augmente la résolution et la luminosité. Il s’avère que l’intensité est proportionnelle au carré de la tension. De plus, nous nous intéressons à l’intensité en tant que fonction de la fréquence et du temps (le quand et le où d’un signal potentiel). »
Pour y parvenir, explique M. Brzycki, les astronomes commencent par utiliser des algorithmes qui calculent la puissance de chaque fréquence observée par rapport aux données de la série chronologique d’entrée. En d’autres termes, l’algorithme transforme les données du signal radio d’une fonction d’espace et/ou de temps en une fonction dépendant de la fréquence spatiale ou de la fréquence temporelle, c’est-à-dire une transformation de Fourier (TF). En élevant cette dernière au carré, les astronomes peuvent mesurer l’intensité de chaque fréquence au cours de la période de collecte des données.
« Pour obtenir un spectrogramme complet, un tableau de l’intensité en fonction du temps et de la fréquence, nous prenons une section de la série tension-temps, nous obtenons la TF, puis nous répétons ce processus sur l’ensemble de l’observation, de sorte que nous pouvons effectivement empiler une série de tableaux de données des la TF les uns sur les autres dans le sens du temps », ajoute Brzycki. « Une fois la résolution temporelle choisie, nous déterminons le nombre d’échantillons temporels nécessaires et calculons la TF pour voir quelle puissance se trouve dans chaque intervalle de fréquence. »
Le principal algorithme de recherche utilisé par les chercheurs du SETI est connu sous le nom d’algorithme « de Doppler à arbre incohérent », qui décale le spectre des ondes radio pour corriger la dérive de fréquence et maximiser le rapport signal/bruit d’un signal. Le programme de recherche SETI le plus complet jamais mis en place, Breakthrough Listen, utilise une version libre de cet algorithme, connue sous le nom de TurboSETI, qui a servi de base à de nombreuses recherches de « technosignatures » (c’est-à-dire de signes d’activité technologique). Comme l’explique Brzycki, cette méthode présente quelques inconvénients : « L’algorithme part du principe qu’un signal SETI potentiel est continu avec un cycle d’utilisation élevé (ce qui signifie qu’il est presque toujours activé). La recherche d’un signal sinusoïdal continu est une bonne première étape car il est relativement facile et peu coûteux en énergie pour les humains de produire et de transmettre de tels signaux.
« Étant donné que le TurboSETI est ciblé sur les signaux en ligne droite qui sont toujours « allumés », il peut avoir du mal à détecter d’autres morphologies, comme les signaux à large bande et pulsés. D’autres algorithmes sont en cours de développement pour tenter de détecter ces autres types de signaux, mais comme toujours, l’efficacité de nos algorithmes dépend des hypothèses que nous formulons sur les signaux qu’ils ciblent. »
Pour les chercheurs du SETI, l’apprentissage automatique est un moyen d’identifier les transmissions dans les données brutes de radiofréquences et de classer plusieurs types de signaux. Le principal problème, selon Brzycki, est que la communauté astronomique ne dispose pas d’un ensemble de données de signaux ET, ce qui rend difficile l’apprentissage supervisé au sens traditionnel. À cette fin, Brzycki et ses collègues ont développé une bibliothèque open-source basée sur Python, appelée Setigen, qui facilite la production d’observations radio synthétiques.
« Setigen facilite la production de signaux SETI synthétiques, qui peuvent être utilisés dans des données entièrement synthétiques ou ajoutés à des données d’observation réelles pour fournir un bruit de fond et des interférences radioélectriques plus réalistes », a déclaré Brzycki. « De cette façon, nous pouvons produire de grands ensembles de données de signaux synthétiques pour analyser la sensibilité des algorithmes existants ou pour servir de base à l’apprentissage automatique. »
Cette bibliothèque standardise les méthodes de synthèse pour l’analyse des algorithmes de recherche, notamment pour les produits de données d’observation radio existants comme ceux utilisés par Breakthrough Listen. « Ceux-ci se présentent à la fois sous forme de spectrogrammes et de tensions complexes (séries temporelles), de sorte que disposer d’une méthode de production de données fictives peut être vraiment utile pour tester le code de production et développer de nouvelles procédures », a ajouté M. Brzycki.

L’une des 42 antennes du réseau de télescopes Allen qui recherche des signaux en provenance de l’espace. Crédit : Seth Shostak / Institut SETI.
Actuellement, des algorithmes pour les observations multifaisceaux sont développés en utilisant Setigen pour produire des signaux fictifs. La bibliothèque est également constamment mise à jour et améliorée au fur et à mesure que la recherche du SETI progresse. Brzycki et ses collègues espèrent également ajouter un support pour la synthèse de signaux à large bande afin d’aider les algorithmes de recherche qui ciblent les signaux à bande non étroite. Des enquêtes du SETI plus robustes seront possibles dans un avenir proche, lorsque les radiotélescopes de nouvelle génération seront opérationnels.
C’est le cas de Breakthrough Listen, qui intégrera les données du réseau MeerKAT en Afrique du Sud. Il y a aussi le Square Kilometre Array (SKA), un projet de radiotélescope massif qui combinera les données d’observatoires situés en Afrique du Sud et en Australie. Il s’agit du réseau MeerKAT et du réseau HERA (Hydrogen Epoch of Reionization Array) en Afrique du Sud, ainsi que du réseau ASKAP (Australian SKA Pathfinder) et du réseau MWA (Murchison Widefield Array) en Australie.
Hélas, il reste le facteur le plus limitatif concernant le SETI, à savoir notre cadre de référence extrêmement limité. En fin de compte, les astronomes n’ont aucune idée de ce à quoi ressemblerait un signal extraterrestre, car nous n’en avons jamais vu auparavant. Paradoxalement, cela rend plus difficile la recherche de technosignatures dans le bruit de fond du cosmos. Les astronomes sont donc contraints d’adopter l’approche du « fruit le plus mûr », c’est-à-dire de rechercher une activité technologique telle que nous la connaissons.
Cependant, en établissant des paramètres basés sur ce qui est théoriquement possible, les scientifiques peuvent restreindre la recherche et augmenter les chances de trouver quelque chose un jour.
Comme le résume Brzycki :
« La seule solution potentielle à ce problème est une sorte d’enquête d’apprentissage automatique non supervisée qui minimise nos hypothèses ; des travaux sont en cours sur ce front. Setigen repose certainement sur cette hypothèse – les signaux synthétiques que l’on peut produire sont de nature heuristique, dans la mesure où c’est l’utilisateur qui décide à quoi ils doivent ressembler.
« En fin de compte, la bibliothèque fournit un moyen d’évaluer nos algorithmes existants et de créer des ensembles de données de signaux potentiels pour développer de nouvelles méthodes de recherche, mais les questions fondamentales du lieu et du moment resteront toujours d’actualité.
Dans des moments comme celui-ci, il est bon de se rappeler que le paradoxe de Fermi ne doit être résolu qu’une seule fois. Dès que nous détecterons une transmission radio dans le cosmos, nous saurons avec certitude que nous ne sommes pas seuls dans l’Univers, qu’une vie intelligente peut exister et existe effectivement au-delà de la Terre et qu’elle communique à l’aide de technologies que nous pouvons détecter.
Écrire commentaire